
起因
前两天找了部阿三悬疑片看,发现全网居然没有一个公开的中文字幕,当然也有可能是我没找到。
于是我找了一圈在线翻译的工具都不太理想,要么容易翻译出错,要么好不容易翻译完成下载的时候需要登录。于是抱着自己动手,丰衣足食的想法诞生了这个工具。
需求
在开始通过AI开发之前我需要规划好这个工具需要实现什么功能,怎么实现的大概框架。规划好之后就可以丢给AI让它输入详细的需求文档。下面是我第一次要求AI生成的需求文档:
帮我创建一个网页字幕文件翻译的项目文档,以便ai工具理解并生成。需要包含项目使用的技术方案,功能需要支持SRT格式字幕文件翻译,可自定义专有名词翻译(可选)、可以选择目标语言、可以自定义翻译ai的api如gemini,openai,deepseek等。api设置需要可以自定义api秘钥,api请求URL、自定义模型。并有一个字幕文件预览框。下载字幕时需要可以选择仅原字幕、仅翻译后的字幕、双语字幕(原文/译文)、双语字幕(译文/原文)。以及一个现代化的前端显示页面。所有api和字幕文件只保存在本地。之后AI返回了需求文档,直接将文档丢给AI工具就行了。不过建议再让AI分析下可行性和遗漏,我就是没检查才后面又折腾。
点击查看AI返回的文档
网页字幕翻译工具项目文档
一、项目概述
开发一个基于浏览器的SRT字幕文件翻译工具,支持多AI引擎对接、本地化存储和灵活的双语字幕生成功能,提供现代化交互界面。
二、技术方案
1. 技术栈
| 模块 | 技术方案 |
|---|---|
| 前端框架 | React 18 + TypeScript |
| UI组件库 | Material-UI 5 + CSS Modules |
| 本地存储 | IndexedDB + localForage |
| 文件解析 | srt-parser-2 |
| 翻译引擎 | 通用AI接口适配器 |
| 构建工具 | Vite |
2. 架构设计
[前端]
├─ 文件上传模块
├─ 翻译配置面板
├─ 实时预览组件
└─ 下载控制模块
│
[本地存储]
├─ 字幕文件存储 (IndexedDB)
├─ API配置存储 (localStorage)
└─ 专有名词库 (IndexedDB)三、核心功能规范
1. 文件处理模块
- SRT文件验证(正则校验)
- 分段解析与时间戳保持
- 文件元数据展示(总字数/段落数)
2. 翻译配置系统
interface TranslationConfig {
targetLang: string; // ISO 639-1标准
apiProvider: 'openai' | 'gemini' | 'deepseek' | 'custom';
apiConfig: {
endpoint: string;
apiKey: string;
model: string;
temperature?: number;
};
terminology: Map<string, string>; // 专有名词映射
}3. AI接口适配层
- 统一请求格式转换
- 错误重试机制(指数退避)
- 速率限制管理
4. 预览模块
- 双栏对比视图(原文/译文)
- 时间轴同步滚动
- 段落高亮定位
5. 输出生成系统
支持四种输出模式:
- Original (源文件)
- Translated (纯译文)
- Bilingual [Source/Target]
- Bilingual [Target/Source]
四、UI/UX设计规范
1. 布局方案
<MainLayout>
<FileUploadPanel />
<ConfigSection collapsible>
<TranslationSettings />
<APIConfiguration />
<TerminologyEditor />
</ConfigSection>
<PreviewSection splitView>
<SourcePreview />
<TranslatedPreview />
</PreviewSection>
<DownloadControl />
</MainLayout>2. 交互流程
graph TD
A[上传SRT] --> B[解析验证]
B --> C[配置翻译参数]
C --> D[执行翻译]
D --> E[实时预览]
E --> F{修改配置?}
F -- Yes --> C
F -- No --> G[选择输出格式]
G --> H[生成下载]五、安全与存储方案
1. 数据安全
- API密钥加密存储(Web Crypto API)
- 敏感数据内存隔离
- 沙箱化翻译进程
2. 存储结构
// IndexedDB Schema
{
files: [
{
id: UUID,
original: ArrayBuffer,
translated: JSON,
metadata: {
duration: number,
wordCount: number
}
}
],
terminologies: [
{
domain: string,
mappings: Map<string, string>
}
]
}六、开发里程碑
| 阶段 | 交付内容 | 周期 |
|---|---|---|
| Phase1 | 核心文件处理与基本翻译流程 | 2周 |
| Phase2 | 多AI引擎支持与配置系统 | 1.5周 |
| Phase3 | 高级预览与输出生成系统 | 1周 |
| Phase4 | 安全增强与性能优化 | 0.5周 |
七、测试方案
1. 测试用例
- 大文件压力测试(>10万字符)
- 跨时区时间戳保持验证
- API故障切换测试
- XSS注入防护测试
2. 性能指标
- 初始加载时间 < 2s
- 翻译吞吐量 > 500字符/秒
- 内存占用 < 300MB
八、扩展性设计
- 插件式翻译引擎接入
- 云端配置同步接口预留
- 字幕样式自定义扩展点
- 多文件批处理架构支持
九、依赖管理
// 关键依赖项
{
"dependencies": {
"react": "^18.2.0",
"material-ui": "^5.14.0",
"localforage": "^1.10.0",
"srt-parser-2": "^2.1.2",
"web-streams-polyfill": "^3.2.1"
}
}本方案采用现代Web技术栈实现安全、高效的本地化字幕翻译工具,兼顾扩展性和用户体验,可支持后续功能演进。
开发
开发工具我选择的是腾讯云的codebuddy,这时候有人要问了为什么不用Cursor?当然是该省省该花花没钱。没错,腾讯云codebuddy是免费的(无广告)。但是会有额度限制,超过限制后会变傻,不过对于我这个需求是够用的,大不了第二天继续。
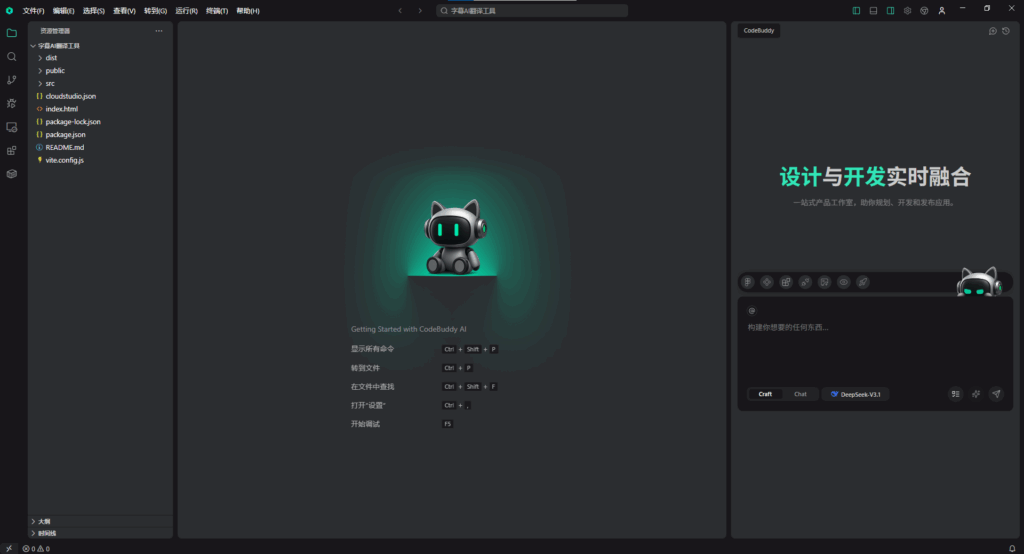
输入上面生成的需求文档,选择Craft模式,回车启动!剩下的就可以交给AI了。
痛苦
没错,就是痛苦。AI创建工具很快,但是实际测试时会发现一堆问题,例如:
- 第一次生成的工具是带后端的,出现了API和WebSocket功能需要经过后端中转的问题,当然这是我文档没描述清楚。好在后面及时发现修改为纯前端,也就是所有文件、请求等都在本地处理,不存在任何上传和服务器存储。
- 之后就是增加功能和修复bug,这些都需要精准描述需求与问题,不然AI很容易擅作主张增加和修改/删除内容。
- 还有当工具超过额度限制时,会经常出现重复一个工作流程的问题和给代码里的函数塞中文字符。
当然,以上问题都不是问题,都是我的问题,codebuddy都免费给你用了还要什么自行车。
上线
花了一坤天的功夫,经过本地多次测试基本没有问题了。直接使用腾讯云EdgeOne的Pages一键启动!(我在codebuddy里链接EdgeOne一直失败,不知道啥原因)
再用免费的EdgeOne一键加速,直接一条龙服务,不愧是良心云。
最后
简单介绍一下工具,工具的功能完全免费不需要登录,工具是一个纯前端项目,所有文件都是在本地处理的,API请求也是本地直连,没有任何数据上传到服务器。
- 翻译配置:工具目前仅支持DeepSeek的API,支持自定义API地址、模型语言以及自定义名词。
- 配置管理:支持保存/加载翻译配置,以及秘钥轮询与多线程功能。
- 字幕编辑:支持手动/AI翻译已经筛选功能。
- 输出选项:支持多种格式输出
- 其它:原文/译文一致性检测,翻译进度日志,未翻译字幕检测等等
折腾这个小工具完全是为了解决自己看电影没有对应字幕的问题,在这里记录下同时把工具分享出来,希望对你有所帮助。
感叹AI是真牛逼,我这种零基础小白也能通过它实现自己的一些需求。

0条评论